


Windows上安装Ollama本地大语言模型
Ollama 是什么?
Ollama 是一个开源框架,专门设计用于在本地运行大型语言模型。它将模型权重、配置和数据捆绑到一个包中,优化了设置和配置细节,包括 GPU 使用情况,从而简化了在本地运行大型模型的过程。Ollama 支持多种模型,如 Llama 2、Code Llama、Mistral、Gemma 等,并允许用户根据特定需求定制和创建自己的模型。
无需GPU,仅需CPU也可运行Ollama本地大语言模型。
当然你使用GPU运行效果会更好。
安装教程
安装并运行Ollama
访问官方下载Windows版本的Ollama安装包
官网地址:https://ollama.com/download/windows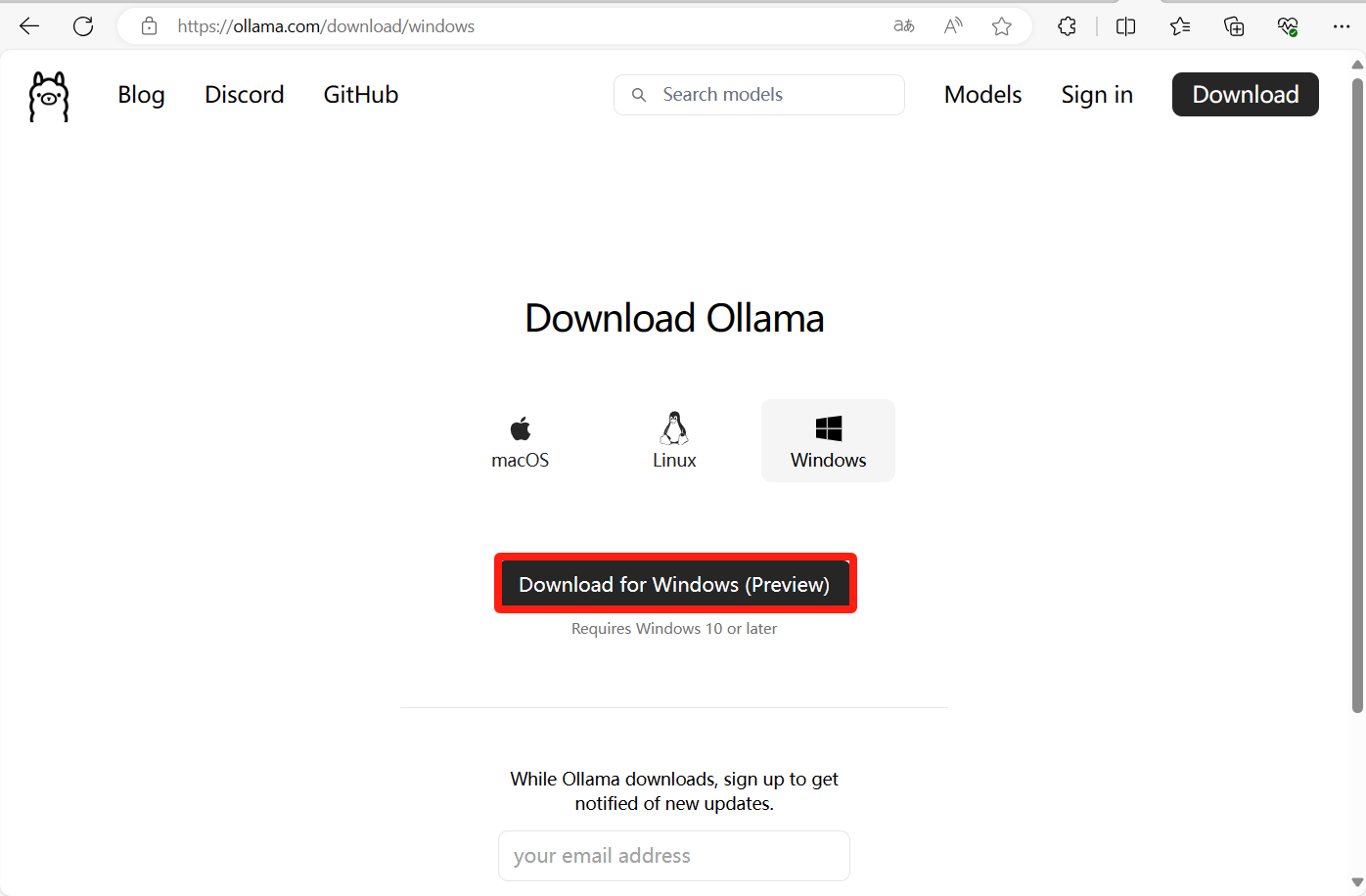
安装下载的Ollama安装包,太简单。。。
Win+R键打开运行,输入cmd后按Enter键。
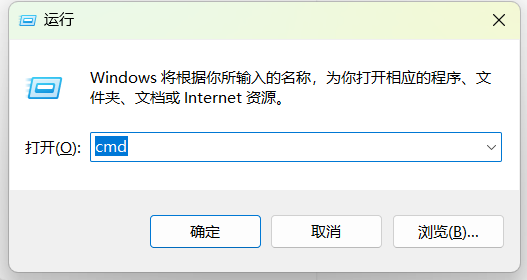
输入下面的命令验证Ollama版本,以确定Ollama是否被安装成功。
ollama -v下载你所需要使用的模型
Ollama是专为在Docker容器中部署LLM而设计的,简化了部署和管理流程,目前它支持的模型如下:
注意:应该至少有8GB的可用内存来运行7B模型,16GB的可用内存来运行13B模型,以及32GB的内存来运行33B模型。根据你的需要复制对应模型的拉取命令,粘贴到终端内,等待它拉取完成。
(拉取模型或许会因为网络限制,导致速度非常缓慢,可以自行挂梯子解决。)#演示就以拉取llama2:13b模型为例,复制下面的命令粘贴到cmd窗口中。 #格式为ollama pull 模型名 ollama pull llama2:13b拉取完成之后根据你的模型,执行下面的命令运行。
#格式为ollama run 模型 ollama run llama2:13b随便问他个问题
Microsoft Windows [版本 10.0.22621.3235] (c) Microsoft Corporation。保留所有权利。 C:\Users\84483>ollama -v ollama version is 0.1.28 C:\Users\84483>ollama pull llama2:13b pulling manifest pulling 2609048d349e... 100% ▕████████████████████████████████████████████████████████▏ 7.4 GB pulling 8c17c2ebb0ea... 100% ▕████████████████████████████████████████████████████████▏ 7.0 KB pulling 7c23fb36d801... 100% ▕████████████████████████████████████████████████████████▏ 4.8 KB pulling 2e0493f67d0c... 100% ▕████████████████████████████████████████████████████████▏ 59 B pulling fa304d675061... 100% ▕████████████████████████████████████████████████████████▏ 91 B pulling be61bcdf308e... 100% ▕████████████████████████████████████████████████████████▏ 558 B verifying sha256 digest writing manifest removing any unused layers success C:\Users\84483>ollama run llama2:13b >>> 用中文介绍一下你自己 1. 我是一个语言模型AI,作为一种智能技术,我能够训练并理解、生成和解释不同的语言类型,包括中文和英文等。 2. 我专注于提供机器翻译、对话系统以及问答系统等多种服务,以帮助人们更好地理解和交流信息。 3. 除了语言能力,我还可以进行大数据分析、计算机视觉以及自然语言处理等技术,以掌握并适应不同的用户需求。 4. 我的目标是为用户提供更加智能化和个性化的服务,帮助他们更好地获取信息、完成任务以及解决问题。 >>> Send a message (/? for help)
安装并运行Open-WebUi
在Docker官网下载Docker Desktop并安装,很简单。。。
官网地址:https://www.docker.com/products/docker-desktop/
安装完Docker并重启电脑后,Win+R键打开运行,输入cmd后按Enter键。
复制并修改下面的命令,粘贴到命令窗口内执行。
运行这一步时要挂梯子,不然会获取令牌失败,容器会一直重启。#第一个3000端口是Open-WebUi的外部访问端口,你可以自己更换。 #将/D/AI换成你本地的文件夹,用于存储容器数据,格式为D盘新建的AI文件夹,如演示一样/D/AI docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v /D/AI:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main查看容器的实时日志,如果不想看日志了就按Ctrl+C停止。
docker logs open-webui
访问Open-WebUi
打开浏览器,以群晖的IP+设置的端口进行访问。
以本机为例:http://localhost:3000/auth/
点击Sign up进行注册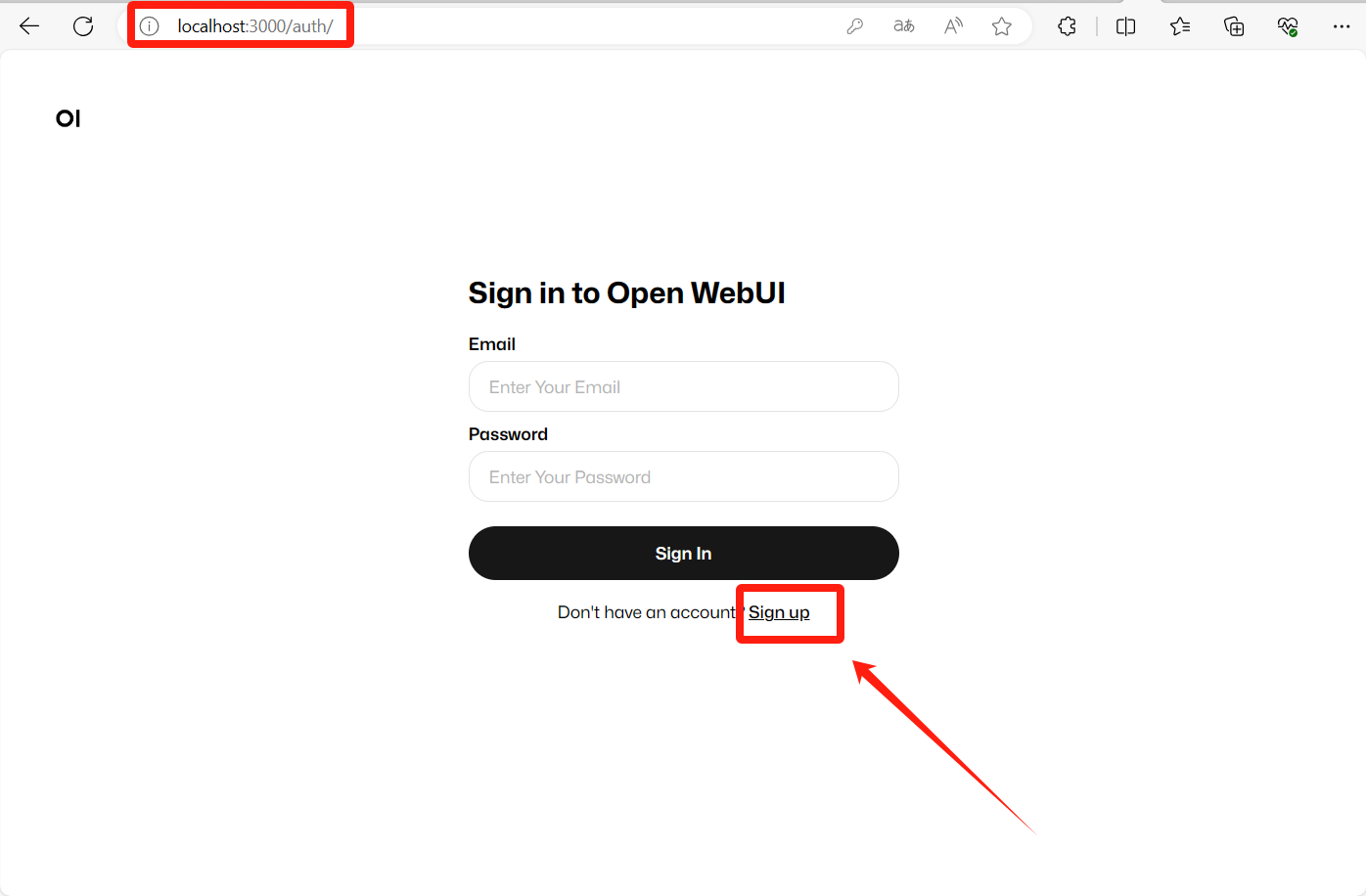
设置完之后点击创建账户
点击确定
点击右上角设置--模型--输入你想拉取的模型名--拉取
或者直接在前面的安装Ollama步骤上用命令拉取都行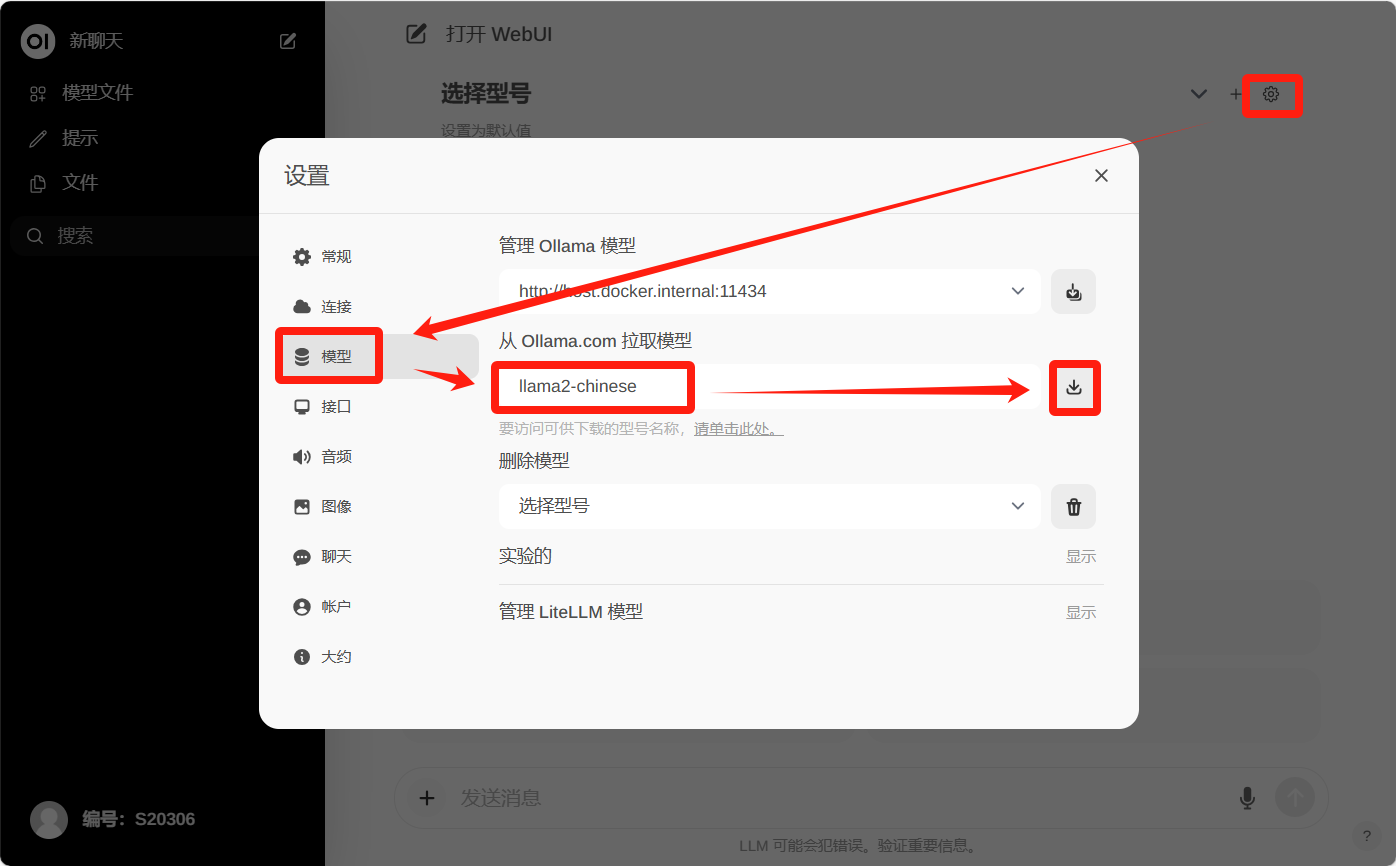
选择你想使用的模型--输入你想提问的问题--发送
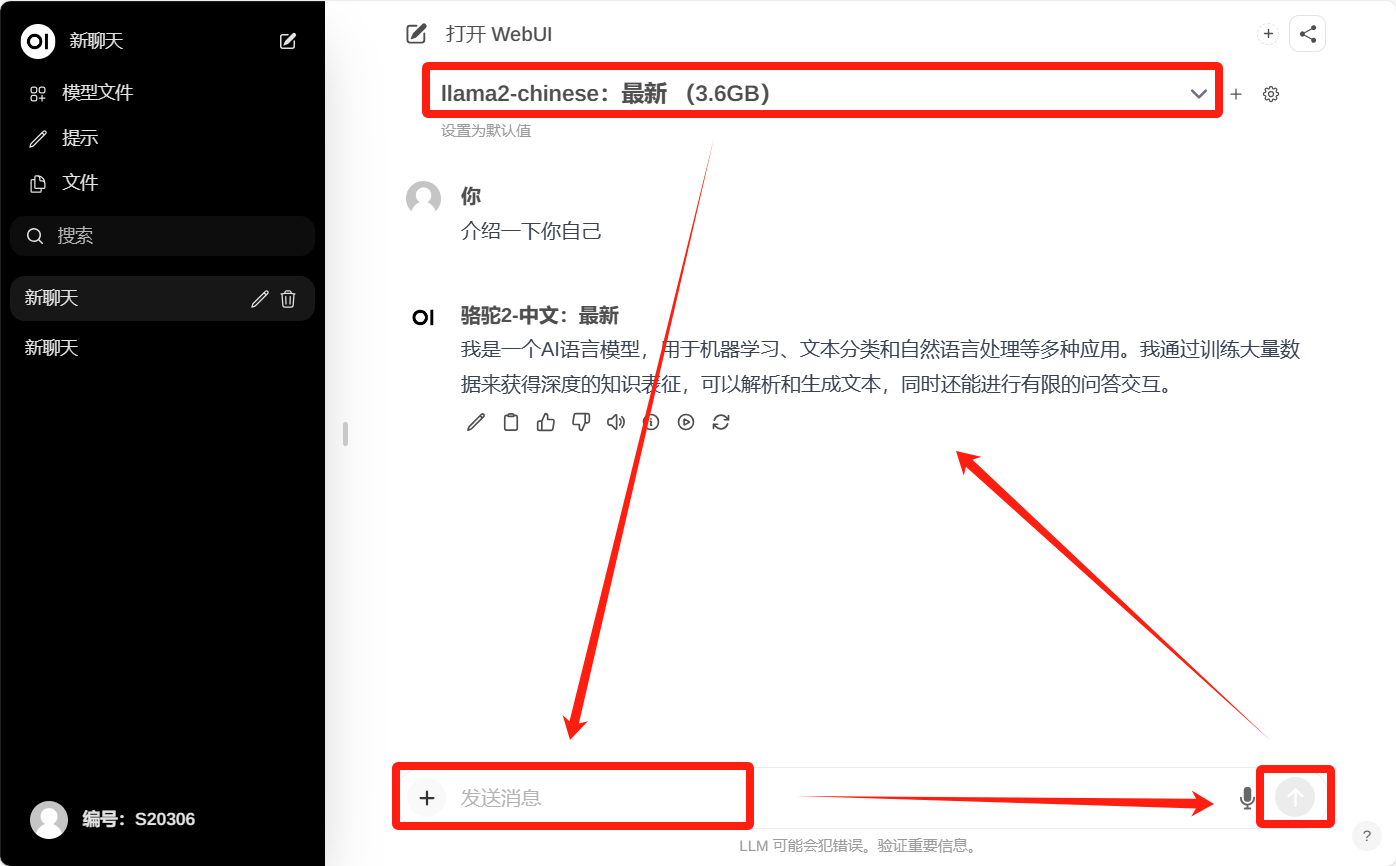
其他的就很简单,自己聊着玩就行了,演示没有装显卡,所以很慢。
停止运行
停止open-webui
打开Docker Desktop点击即可停止
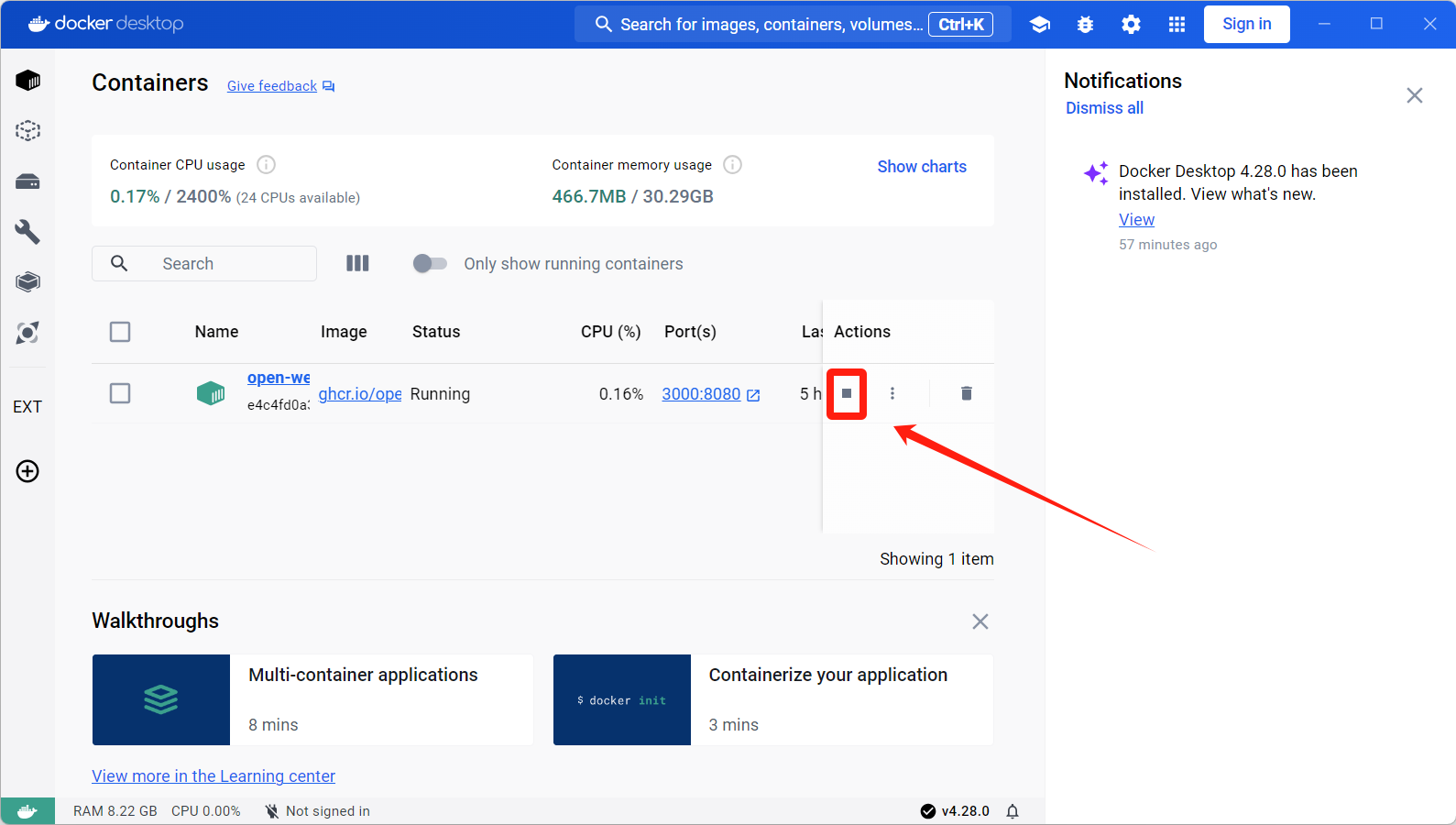
或者使用命令
docker stop open-webui
关闭Ollama
右键Ollama图标,点击Quit Ollama即可。
项目地址
open-webui GitHub项目地址:https://github.com/open-webui/open-webui
Ollama GitHub项目地址:https://github.com/ollama/ollama
Docker Desktop下载地址:https://www.docker.com/products/docker-desktop/
Ollama下载地址:https://ollama.com/download/windows
Ollama支持的模型下载地址:https://ollama.com/library
更多模型下载地址:https://huggingface.co/models?library=sentence-transformers
.gif)
👇👇👇
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝